

今天介紹下ST官方剛剛推出的CubeMx 自帶的X-CUBE-AI(Artificial intelligent)插件功能,可以給現有的STM32 M3-M7高性能的處理器添加基于訓練好的ANN 的模型用于不同的數據分析處理。
使用STM32Cube.AI簡化了人工神經網絡映射
1.可與流行的深度學習培訓工具互操作
2.兼容許多IDE和編譯器
3.傳感器和RTOS無關
4.允許多個人工神經網絡在單個STM32MCU上運行
5.完全支持超低功耗STM32MCU
提高您的工作效率
利用DeepLearning的強大功能提高信號處理性能并提高STM32應用程序的生產率。創建人工神經網絡并將其映射到STM32(通過CubeMx自動生成優化的代碼),而無需手動構建代碼。
以上就做個簡短的介紹,想了解更多有關STM32Cube.AI可以訪問下面的鏈接:
那先前的準備工作就是需要安裝最新版本的CubeMx 5.0.1
然后使用CubeMx 去安裝X-CUBE-AI插件, 700多M的容量。。慢慢下載吧

下載好后,CubeMx里的Artificial intelligent
激活Enable

這里我們就可以看到里面的選項了
下載下來。。然后選擇Keras 的AI API算法

model.h5就是我們需要導入到工程里的AI Keras的訓練好的模型
Human Activity Recognition Using Convolutional Neural Network in Keras
人類活動識別卷積神經網絡算法模型
然后我們導入到工程里
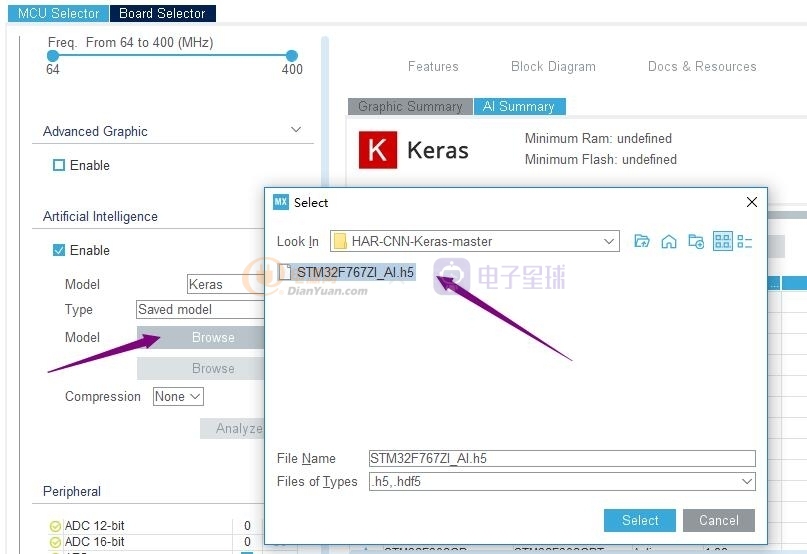
這里選擇壓縮參數,不同的壓縮參數對MCU的flash容量
要求也不一樣。。

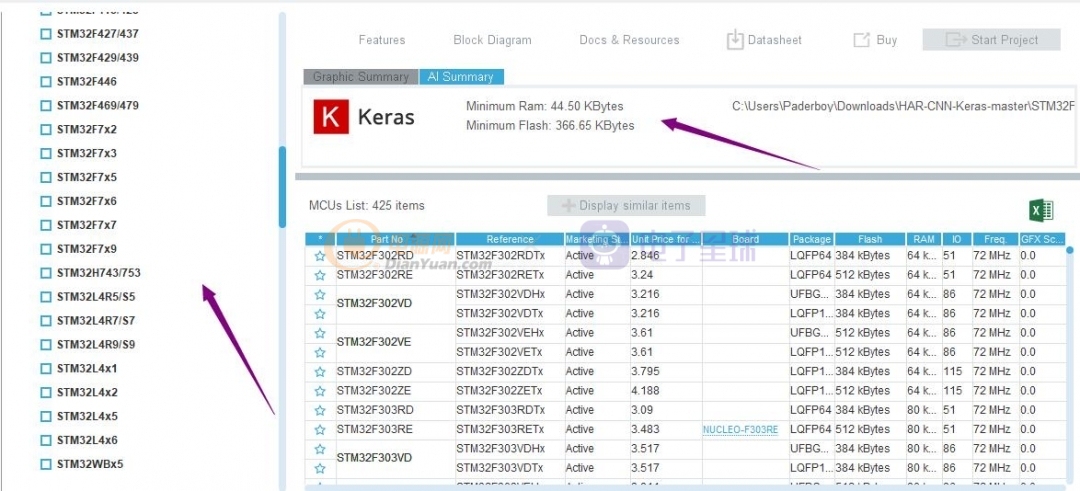
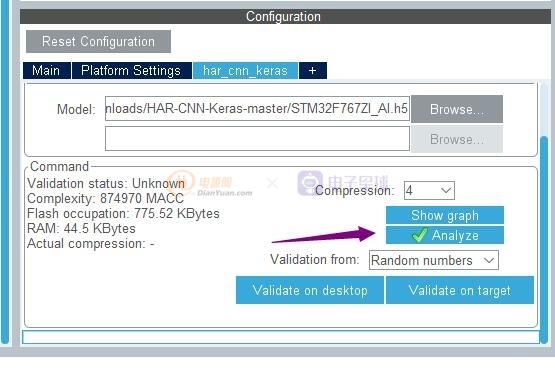
點擊Analyze cube就好計算使用這個神經網絡算法的ram和flash容量占用

好了結果出來了,

經過分析后Cube會自動列出可以使用的MCU
然后顯示在列表里
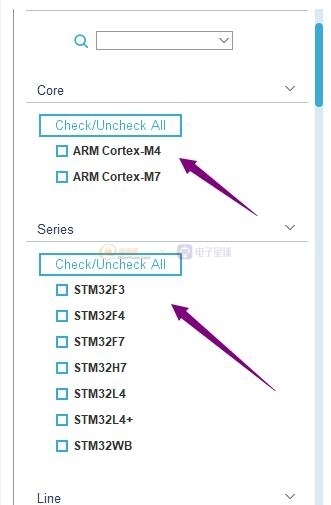
這里舉個例子,我們選擇沒有壓縮優化
分析模型算法后的結果我沒有匹配的MCU可以使用

這是選擇壓縮比參數8的結果,可以支持很多的MCU使用這個
神經網絡算法。。
好了,這里我們就選擇STM32F767ZI Nucleo 板卡作為
這次演示使用的板卡
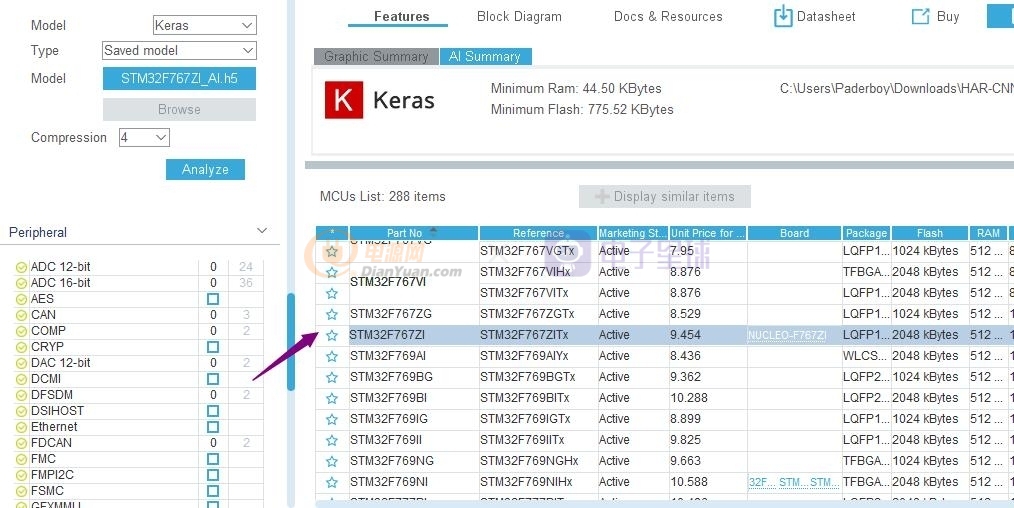
好了選擇好了,板卡,我們還需要給它添加
擴展庫,也就是AI庫

選擇好Validation 和打勾 AI core

然后在cube 左下方可以看到下圖箭頭
提示的插件功能
我們需要打勾以下2個功能
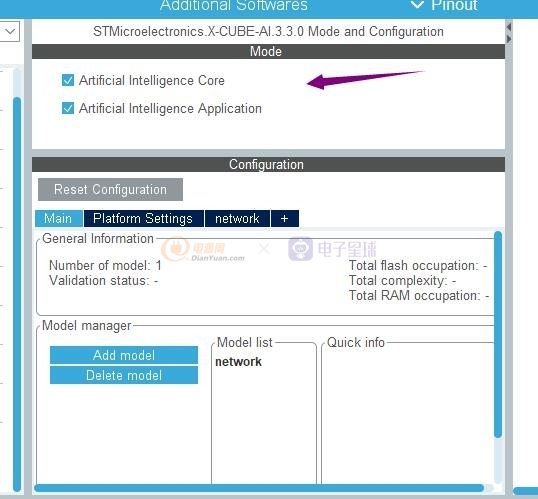
然后創建我的AI算法名稱,這個名稱會在后續的
里自動創建好。
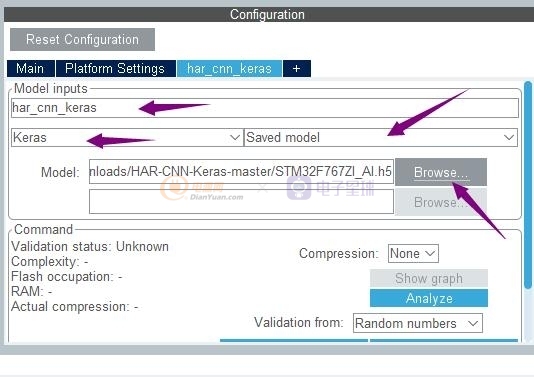
添加好,我們下載好的AI神經網絡算法,
然后再Analyze下就好。。打勾表示驗證通過
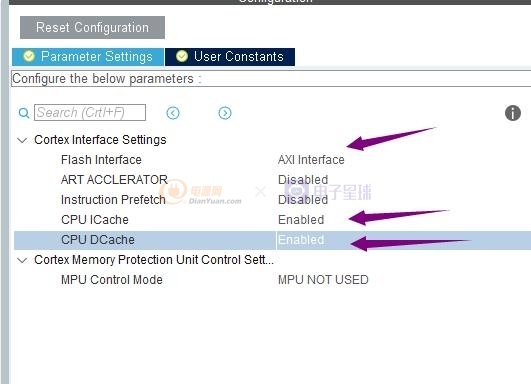
然后我們需要配置我們的mcu的
CPU ICache 和 CPU DCache
然后配置MCU主頻為216Mhz

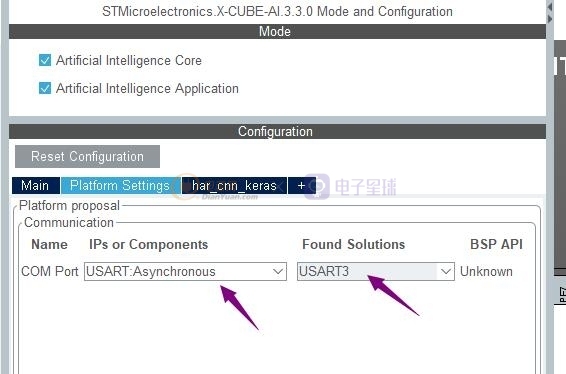
然后我們需要配置串口3和CubeMx進行通訊,驗證我們
工程。。。
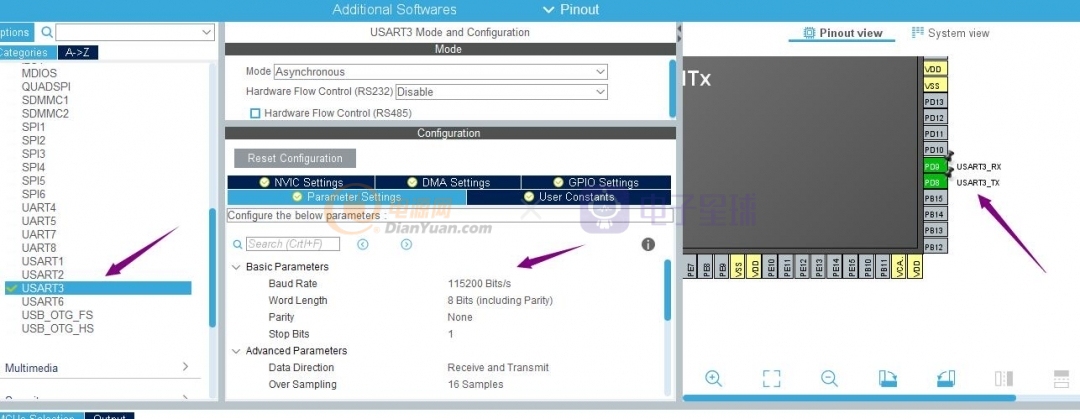
然后在 AI擴展功能里選擇通訊端口為串口3
好了,工程差不多創建好了。接下來就是
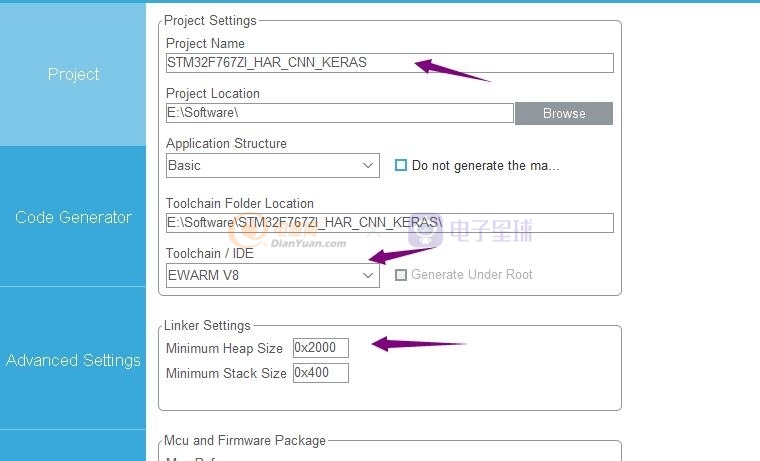
配置工程的路徑好
我們配置使用IAR 編譯環境。。
然后Heap 然后要配置到2000 這個很重要,要是設置少了
系統就會奔潰(切記)
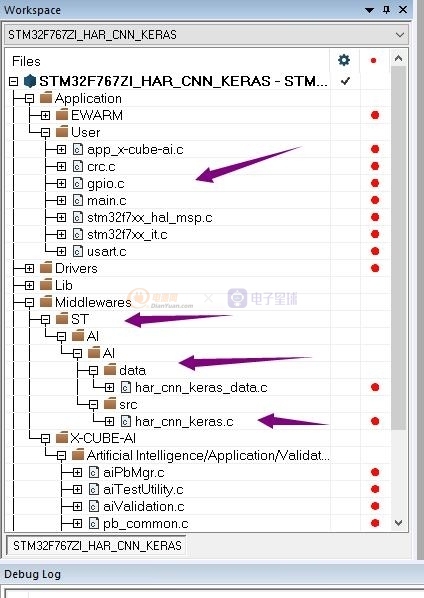
好了工程生成好了,我們就可以 使用IAR 打開工程了
工程如下,工程里自動生成了基于AI的算法的所以文件
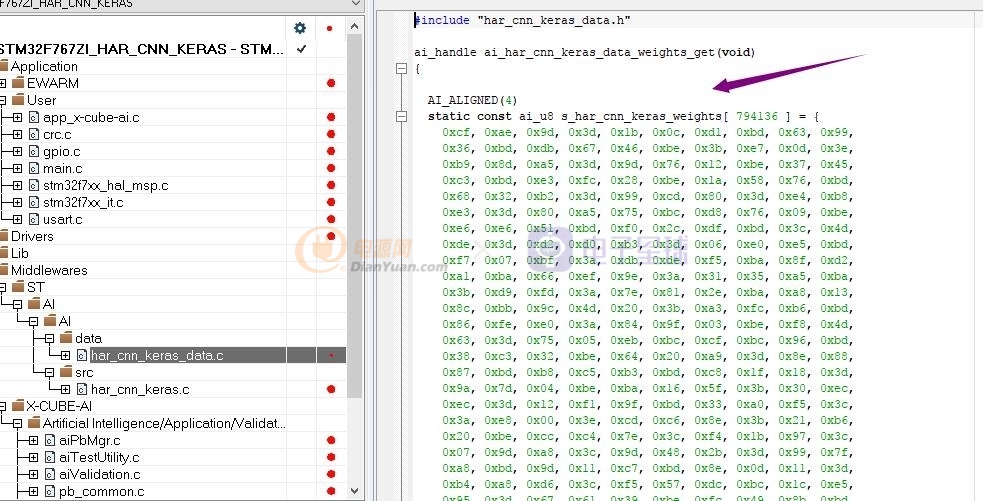
這里可以看到,基于AI訓練好的模型數據列表。。。
好了,配置位STLINK,然后編譯好就可以直接下載到
板子上了


好了,現在我們需要回到CubeMx里,回到
AI擴展功能里。。 先重啟下開發板,然后
點擊Validation on target

選擇手動,然后選擇對應的串口端口
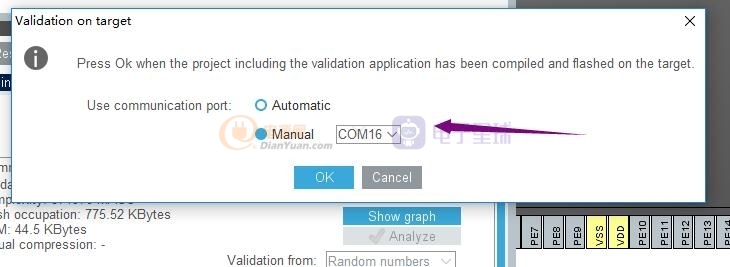
這里可以看到驗證已經開始了‘
’
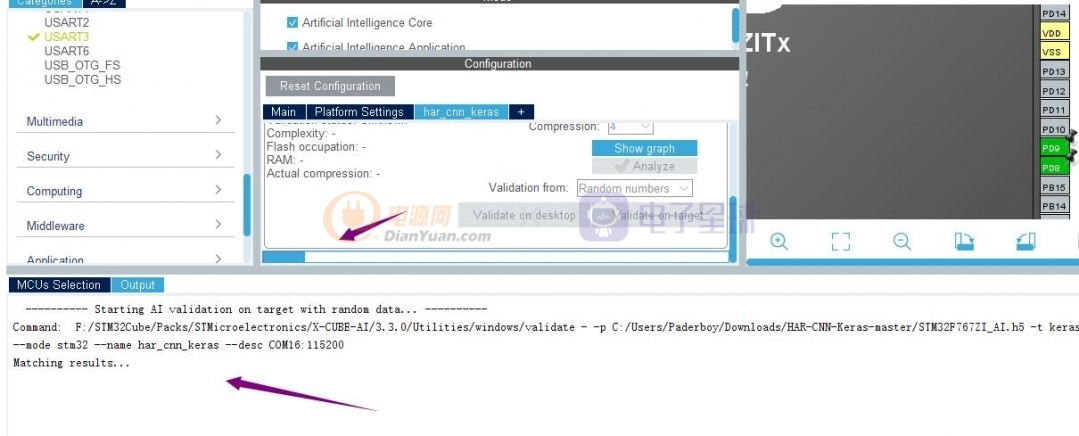
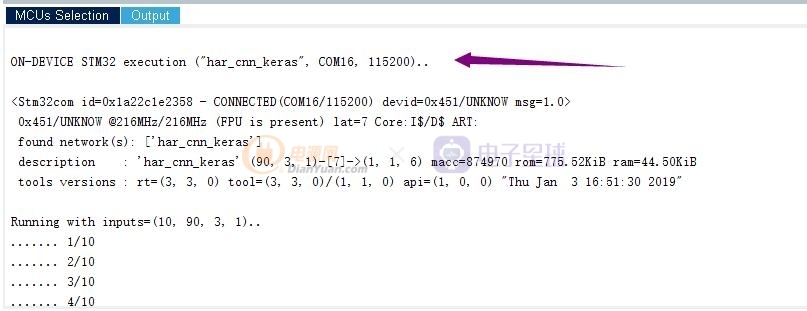
好了,結果出來了。我們可以在串口輸出的信息里看到
有關的數據

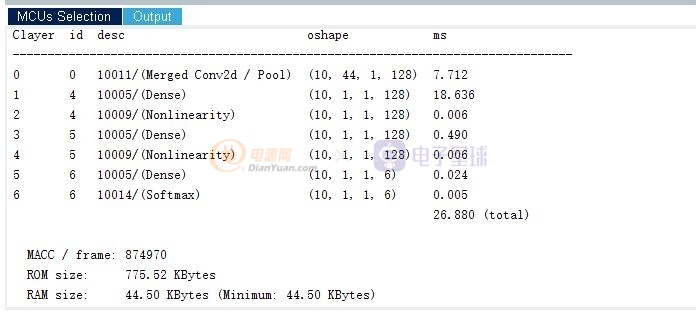
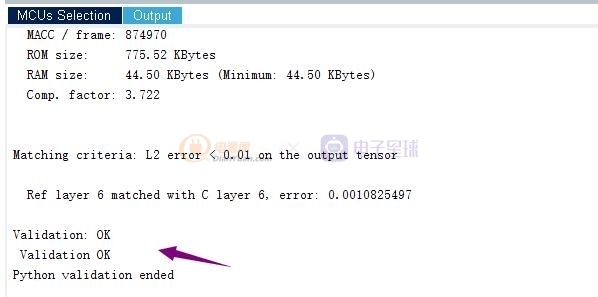
好了,基于CubeMx+AI擴展庫的使用就分享到這了